Aporia
Use Aporia to detect PII in requests and profanity in responses
1. Setup guardrails on Aporia
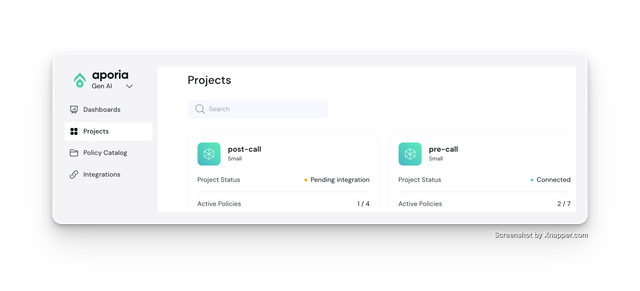
Create Aporia Projects
Create two projects on Aporia
- Pre LLM API Call - Set all the policies you want to run on pre LLM API call
- Post LLM API Call - Set all the policies you want to run post LLM API call
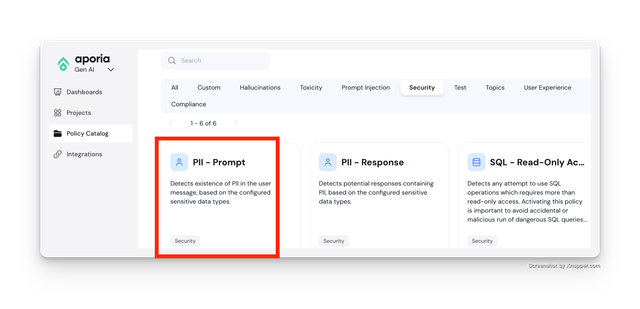
Pre-Call: Detect PII
Add the PII - Prompt to your Pre LLM API Call project
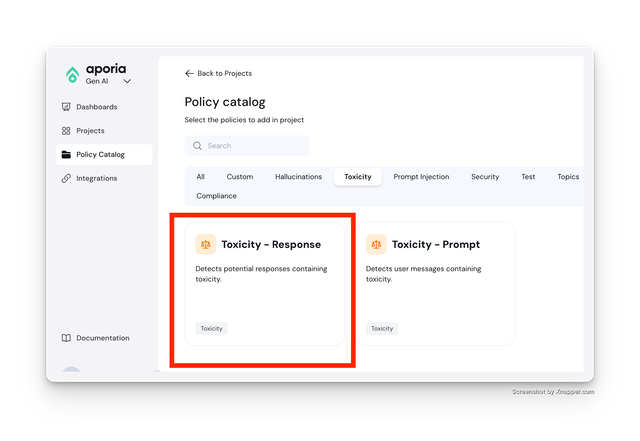
Post-Call: Detect Profanity in Responses
Add the Toxicity - Response to your Post LLM API Call project
2. Define Guardrails on your LiteLLM config.yaml
- Define your guardrails under the
guardrailssection
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: openai/gpt-3.5-turbo
api_key: os.environ/OPENAI_API_KEY
guardrails:
- guardrail_name: "aporia-pre-guard"
litellm_params:
guardrail: aporia # supported values: "aporia", "lakera"
mode: "during_call"
api_key: os.environ/APORIA_API_KEY_1
api_base: os.environ/APORIA_API_BASE_1
- guardrail_name: "aporia-post-guard"
litellm_params:
guardrail: aporia # supported values: "aporia", "lakera"
mode: "post_call"
api_key: os.environ/APORIA_API_KEY_2
api_base: os.environ/APORIA_API_BASE_2
Supported values for mode
pre_callRun before LLM call, on inputpost_callRun after LLM call, on input & outputduring_callRun during LLM call, on input Same aspre_callbut runs in parallel as LLM call. Response not returned until guardrail check completes
3. Start LiteLLM Gateway
litellm --config config.yaml --detailed_debug
4. Test request
Langchain, OpenAI SDK Usage Examples
- Unsuccessful call
- Successful Call
Expect this to fail since since ishaan@berri.ai in the request is PII
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi my email is ishaan@berri.ai"}
],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
Expected response on failure
{
"error": {
"message": {
"error": "Violated guardrail policy",
"aporia_ai_response": {
"action": "block",
"revised_prompt": null,
"revised_response": "Aporia detected and blocked PII",
"explain_log": null
}
},
"type": "None",
"param": "None",
"code": "400"
}
}
curl -i http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-npnwjPQciVRok5yNZgKmFQ" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [
{"role": "user", "content": "hi what is the weather"}
],
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}'
5. ✨ Control Guardrails per Project (API Key)
info
✨ This is an Enterprise only feature Contact us to get a free trial
Use this to control what guardrails run per project. In this tutorial we only want the following guardrails to run for 1 project (API Key)
guardrails: ["aporia-pre-guard", "aporia-post-guard"]
Step 1 Create Key with guardrail settings
- /key/generate
- /key/update
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-D '{
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}
}'
curl --location 'http://0.0.0.0:4000/key/update' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"key": "sk-jNm1Zar7XfNdZXp49Z1kSQ",
"guardrails": ["aporia-pre-guard", "aporia-post-guard"]
}
}'
Step 2 Test it with new key
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-jNm1Zar7XfNdZXp49Z1kSQ' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "my email is ishaan@berri.ai"
}
]
}'